Making of Monkeys.zip (PART ONE)
It’s been one month since the launch of monkeys.zip. In that time, we’ve gathered over 11,000 monkeys, which have written over 6 billion words - completing well over 75% of the words in Shakespeare’s works. In fact, they’ve recently finished writing every four-letter word!

While the initial hype has died down to a small trickle, the monkeys are still typing just as hard as ever, and I figured it’d be a good time to talk about how I built the site. If this part doesn’t interest you, check out PART TWO where I talk all about the monkey names!
Tech Stack
| Backend & Database: | Supabase |
| Frontend Library: | LitHTML |
| 3D Library: | Three.JS |
| Blog: | Astro |
This is a relatively small list of technologies - as I tend to make as much as possible from scratch on my side projects, out of stubbornness. In this project, for example, I made a state management library called StateFarm. It’s awful, don’t use it.
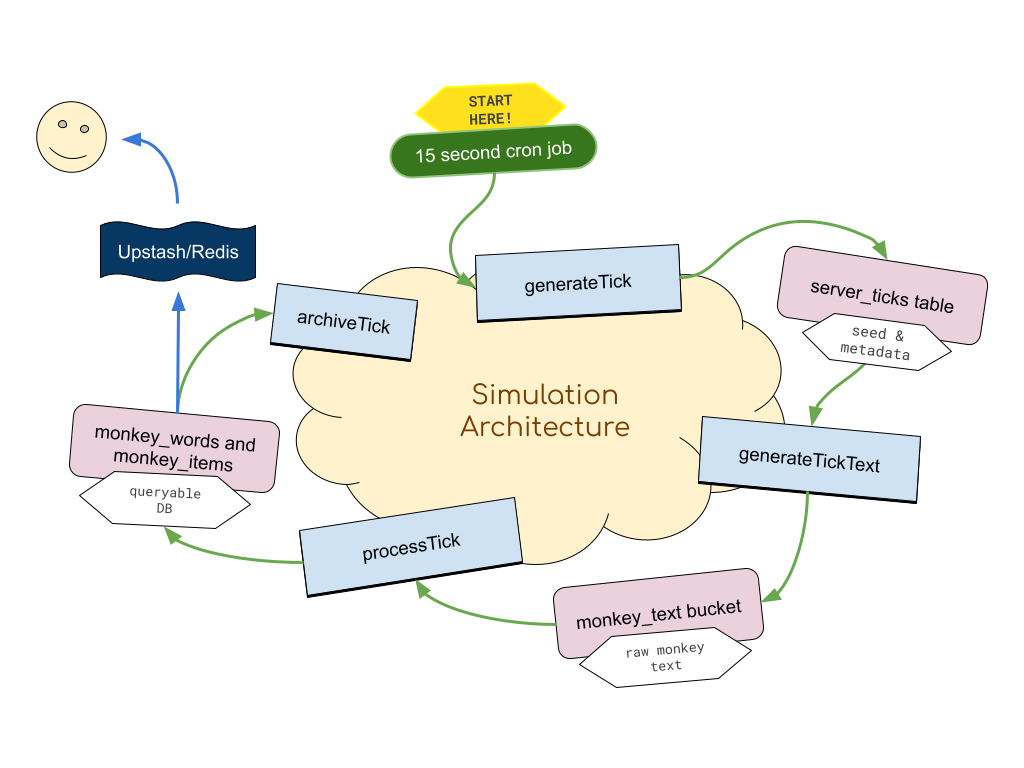
Simulation Architecture
The more interesting stuff is how the backend simulation all comes together - it’s built as a loosely coupled pipeline with four main steps:
Ticks
The first important design decision comes with the concept of Ticks. The backend produces data in 15-second long batches. The above pipeline runs every 15 seconds, producing 15 seconds worth of monkey-text. This interval length was chosen as a tradeoff between reducing runtime of each step, making errors easier to retry and recover from, and spreading out DB load into smaller chunks, while reducing server <—> client bandwidth and requests.
Step One (generateTick)
Every 15 seconds, a cronjob calls a generateTick function - which has only one job - which is to put a new tick row in the ticks table.
| Tick ID | Start Time | Seed | Status |
|---|---|---|---|
| 1234 | 04:13:25 | wn9837xw9873v | NEW |
And that’s all it does! Keeping this step so simple and infallible is crucial to the reliability of later steps. If they fail, or there’s a huge data loss, everything can be rebuilt or retried as needed, as long as we have an entry in this table.
Step Two (generateTickText)
When a new tick is added to this table, the generateTickText is called via a WebHook. This function has the job of generating the text for each monkey for that 15-second tick.
We use sfc32 to deterministically generate random numbers based on the seed, which is the tick seed, merged with the monkey seed. This strategy allows a very deterministic random monkey text generator, that can execute both server-side and client-side.
Once the text is generated, we drop it into a Storage bucket. This isn’t strictly necessary, but I like the transparency. For debugging or investigation purposes, it’s nice to be able to browse all the text that monkeys have written, without having to regenerate it.
Step Three (processTick)
When the text is dropped into Storage, another WebHook is called, which combs through the text and searches for matches against a dictionary. It builds an immense batch update do a number of Tables in our database
monkey_words - Source of truth for every (valid) word every monkey has written
word_counts_cache - Faster for lookups of a given word (EG “monkey” has appeared 100 times)
monkey_items - Any items a monkey is earned is granted to this table
Step Four (Archive)
A more recent addition has been a separate cleanup script which runs on a cron job - the purpose of which is to archive old, short words from the monkey_words table and place them into a monkey_words_archived table - which drastically speeds up reads on monkey_words (which started slowing down at several billion rows).
Other Backend Things
The grid of monkeys is labeled into chunks of 64x64 - which hold almost no value, except for creating a minimum query size for monkeys while scrolling through the app - and allowing me to cache these chunks in Redis. During normal traffic, it’s actually slower (by over 100 ms) to fetch the cached result from Redis than just query the DB for it - but in the early days when the application was being battered by reddit, it was a lifesaver to be able to render the monkeys without the database needing to be responsive.
There’s still a fair amount of optimization that remains to be done. Now that we’re getting into the ‘diminishing returns’ portion of this project, I’d love to speed the monkey typing up, so that we can start carving through the 6 and 7 letter words, but that will require some further architectural changes. I’m largely considering getting a custom VPS with just a big bucket of RAM, and doing this all in-memory, for speed.